Algorytm ewolucyjny przeszukuje przestrzeń alternatywnych rozwiązań problemu w celu odnalezienia rozwiązań najlepszych lub potencjalnie najlepszych. Przeszukiwanie odbywa się za pomocą mechanizmów ewolucji oraz doboru naturalnego.
Artykuł ten jest rozwinięciem skryptu przygotowanego na wykład o identycznym tytule, który wygłosiłem na Wakacyjnych Warsztatach Wielodyscyplinarnych. Wprawdzie w sieci istnieje już pewna liczba materiałów o tym, ale zdecydowana większość ma charakter czysto teoretyczny, gdy tymczasem tutaj chciałbym pozamieszczać kilka fragmentów kodu źródłowego.
Zacznijmy od tego, czym jest algorytm ewolucyjny. Definicja mówi, że przeszukuje on przestrzeń alternatywnych rozwiązań problemu w celu odnalezienia rozwiązań najlepszych lub potencjalnie najlepszych. Zalicza się go do klasy algorytmów heurystycznych. Przeszukiwanie odbywa się za pomocą mechanizmów ewolucji oraz doboru naturalnego. W praktyce te słowa oznaczają, że wykorzystujemy ewolucję, aby poprzez krzyżowanie i mutacje stworzyć z grupy losowych zestawów danych to, co nas będzie satysfakcjonować. Pierwszy algorytm ewolucyjny został zaproponowany przez Johna Hollanda w 1975 roku, który bardzo interesował się biologią i często czerpał z niej inspirację w swych pracach informatycznych.
Nazewnictwo
Większa część nazewnictwa została zaczerpnięta z terminologii biologicznej.
- Osobnik - pojedyncza propozycja rozwiązania problemu.
- Populacja - zbiór osobników, na których operuje algorytm.
- Genotyp - pewna dziedziczna informacja, w którą wyposażony jest osobnik.
- Fenotyp - zestaw cech generowanych na podstawie genotypu, które podlegają ocenie środowiska.
- Kodowanie - proces tworzenia fenotypu z genotypu.
- Funkcja przystosowania - funkcja oceniająca jakość danego osobnika na podstawie jego fenotypu.
- Chromosom - część genomu osobnika. W niniejszym wykładzie wszystkie prezentowane problemy dotyczą osobników o jednym chromosomie.
- Geny - najmniejsze elementy genotypu reprezentujące elementarne informacje. Możliwymi wartościami danego genu są allele.
Zatrzymam się dłużej przy terminie "algorytm genetyczny". Według części źródeł, w tym Wikipedii, jest to grupa algorytmów ewolucyjnych (i to ta, którą w zasadzie będziemy się w tym tekście zajmować), lecz dla wielu ludzi terminy te są synonimiczne.
Zasada działania
Prosty algorytm genetyczny działa w następujący sposób: inicjujemy (najczęściej w sposób losowy) pewną początkową populację osobników i poddajemy każdego z nich ocenie. Następnie z populacji wybieramy osobniki najlepiej do tego przystosowane i za pomocą operacji genetycznych (krzyżowanie oraz mutacja) tworzymy nowe pokolenie, które po ocenie stanie się bazą do kolejnego kroku algorytmu. Na schemacie można to przedstawić w sposób następujący:
procedure AG;
begin
t : = 0;
inicjacja(p[0]);
ocena(p[0]);
while(not warunek_stopu) do
begin
T := selekcja(p[t]);
W := krzyzowanie(T);
ocena(W);
t := t + 1;
p[t] := W;
end;
end;
Legenda
- t - numer pokolenia.
- p[t] - populacja w pokoleniu numer t.
- T - grupa najlepiej przystosowanych osobników wybrana do rozrodu.
- W - nowe pokolenie utworzone w wyniku rozmnożenia grupy osobników T.
- inicjacja() - inicjuje populację startową.
- ocena() - przypisuje każdemu osobnikowi pewną liczbę określającą jakość jego fenotypu.
- selekcja() - wybiera z populacji osobniki o najlepszej jakości.
- krzyzowanie() - za pomocą operacji krzyżowania i mutacji tworzy nowe pokolenie, które zastąpi stare.
Najbardziej wymagającym zadaniem jest właśnie napisanie tych czterech wymienionych funkcji tak, aby prawidłowo rozwiązywały nasz problem. Dlatego zatrzymamy się przy każdej z nich na dłużej.
Warianty ułożenia genów
Wyróżniamy trzy sposoby ułożenia genów w chromosomie:
- Klasyczny - geny na różnych pozycjach przechowują różne informacje. W wyniku krzyżowania geny nie zmieniają pozycji, lecz wartości. Wykorzystywany w problemach, gdzie chcemy dobrać optymalne cechy osobnika.
- Permutacyjny - geny przechowują podobne informacje. W wyniku krzyżowania nie zmieniają wartości, lecz miejsce w chromosomie. Wykorzystywany w problemach kombinatorycznych, np. problemie komiwojażera.
- Drzewiasty - chromosom tworzy złożoną strukturę drzewiastą. W czasie krzyżowania przesunięciom ulegają całe gałęzie genów. Często geny mogą zmieniać także wartości. Wykorzystywany w programowaniu genetycznym oraz tam, gdzie ewolucji podlegają reguły matematyczne.
Funkcja oceny
Na podstawie fenotypu danego osobnika generuje jedną liczbę opisującą jego jakość przystosowania. Np. dla algorytmu genetycznego poszukującego ekstremum funkcji, gdzie genotyp reprezentuje jej argument x, wartością funkcji przystosowania może być po prostu obliczona wartość wyrażenia matematycznego, dla którego poszukujemy ekstremum. Na potrzeby tego artykułu napisałem program, który tworzy populację losowych słów, a następnie za pomocą operacji krzyżowania dąży do utworzenia z nich określonego na początku terminu (np. jak podaliśmy słowo "konsumpcjonizm", to populacja dąży do wykształcenia wśród siebie właśnie takiego osobnika). Kod źródłowy funkcji oceny wygląda tutaj następująco:
float TTextAlgorithm::rateFagas(void *fagas)
{
std::string *s = (std::string*)fagas;
float quality = 0;
for(int i = 0; i < s->length(); i++)
{
if((*s)[i] == comparado[i])
{
quality += 1.0;
}
else
{
quality += (float)((127 - ((*s)[i] - comparado[i]))/50.0);
}
}
return quality;
} // end rateFagas();
Po zainicjowaniu osobnika jako zmiennej std::string oraz licznika oceny, przystępujemy do działania. Porównujemy każdy znak osobnika ze znakiem słowa wzorcowego w zmiennej comparado. Jeżeli na danej pozycji znaki będą takie same, do jakości dodawana jest wartość 1. W innym wypadku jest to różnica między kodami ASCII odjęta od 127 i podzielona przez 50 (będzie większa od 1). Dodam, że im mniejsza wartość funkcji oceny, tym lepszy był osobnik, dlatego teraz wyraźnie widać, iż niezgodność jakiejś litery powoduje znacznie większy skok wartości, czyli pogorszenie osobnika.
Selekcja
Selekcja wybiera z aktualnej populacji grupę najlepiej przystosowanych osobników do dalszego rozrodu. Istotne jest, aby właściwie dobrać stosunek wielkości tworzonej grupy do rozmiaru populacji. Zbyt małe stosunki (np. 1/1000) mogą doprowadzić do zaniku różnorodności genetycznej i defektów fenotypów, natomiast zbyt duże (np. 1/2) powodują wprowadzenie do rozrodu zbyt dużej liczby słabych genów, co również obniża jakość najlepszych osobników. Istnieje kilka metod selekcji:
- Metoda koła ruletki - wyobraźmy sobie koło ruletki, którego tarcza podzielona jest na pewną liczbę wycinków o różnych rozmiarach. Każdy osobnik otrzymuje obszar o rozmiarze wprost proporcjonalnym do jego jakości. Puszczamy koło ruletki w ruch, a po jego zatrzymaniu wskaźnik zatrzyma się na jakimś osobniku, który wchodzi do grupy rozrodczej. Oczywiście im większy obszar dostał dany osobnik, tym większe prawdopodobieństwo jego wylosowania, dlatego też wielkość obszaru przydziela się przeważnie funkcją prawdopodobieństwa (ZW = <0, 1>). Jeśli przez F(i) oznaczymy wartość funkcji przystosowania osobnika i, to prawdopodobieństwo jego przystosowania wyliczymy ze wzoru
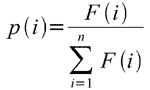
- Selekcja rankingowa - osobniki w populacji są sortowane według ich jakości od najlepszego do najgorszego. Do dalszego rozrodu przechodzi tylko n najlepiej przystosowanych osobników. Metoda ta charakteryzuje się lepszym uwarunkowaniem, niż metoda ruletki.
- Selekcja turniejowa - populację dzieli się na szereg dowolnie licznych grup. Następnie z każdej z nich wybieramy osobnika o najlepszym przystosowaniu. Ten rodzaj selekcji także sprawdza się lepiej, niż metoda ruletki.
Zatrzymajmy się na chwilę przy metodach rankingowej i turniejowej, spróbując określić, jak zmienia się populacja przy stosowaniu każdej z nich. Selekcja rankingowa sprawia, że do rozrodu trafiają zawsze osobniki najlepsze globalnie. Wydawać by się to mogło optymalnym posunięciem, lecz prowadzi do przedwczesnego zaniku różnorodności, a tym samym do zbieżności algorytmu. W selecji turniejowej do rozrodu trafiają zawsze osobniki najlepsze lokalnie, w obrębie grup. Na pewno w jednej z nich znajdzie się osobnik najlepszy globalnie, zatem o przeniknięcie jego genów (i wielu innych) nie trzeba się martwić, ale zachowamy przy tym różnorodność, dopuszczając też osobniki trochę gorsze. Ma to sens, gdyż i one mogą zawierać ciekawe rozwiązania genowe, które jednak ostatecznie są tłumione przez całą resztę genomu. Przykładowa implementacja selekcji turniejowej wygląda następująco:
void TGeneticAlgorithm::selectionCompetition(SFagas **loverList, int lsize)
{
SFagas *tournament[PROPORTION];
int c = 0;
int l = 0;
for(int i = 0; i < fagasAmount; i++)
{
if(c == PROPORTION)
{
geneticQuickSort(tournament, PROPORTION);
loverList[l] = tournament[0];
c = 0;
l++;
}
tournament[c] = population[i];
c++;
}
if(fagasAmount % 2 == 0)
{
geneticQuickSort(tournament, PROPORTION);
loverList[l] = tournament[0];
}
} // end selectionCompetition();
Na początku budujemy sobie tablicę o wielkości PROPORTION - normalnie jest to liczba mówiąca, na ile trzeba podzielić części populację, aby otrzymać grupę do rozrodu stosownej wielkości (tj. jeśli jest równe 20, grupa rozrodcza będzie 20 razy mniejsza, niż populacja). Tu służy do trochę innego celu. Następnie przeglądamy całą populację i wsadzamy osobniki do tablicy turniejowej aż do jej zapełnienia. Kiedy to się stanie, sortujemy ją quicksortem według wartości funkcji oceny i wybieramy pierwszego osobnika (będzie on po posortowaniu na początku tablicy). Wstawiamy go do tabeli rozrodczej loverList i zapełnianie bufora turnieju zaczynamy od początku. Na końcu musimy też uwzględnić, czy ilość osobników w populacji jest parzysta, czy nieparzysta.
Istnieją także strategie ewolucyjne polegające na przenoszeniu części starej populacji do nowego pokolenia bez żadnych zmian, krzyżowań itd.
Crossing-over
Generowanie nowej populacji z najlepiej przystosowanych osobników przeprowadzamy metodą crossing-over (pl. krosowanie). Do jej wykonania potrzebne są dwa osobniki, które rozcinamy w losowo wybranym punkcie i łączymy na krzyż, tj. fragment osobnika A przypinamy osobnikowi B, a fragment osobnika B - do osobnika A:

W wyniku wykonania tej operacji powstają dwa nowe osobniki o wymieszanym materiale genetycznym. Istotny jest tu też sposób wyboru osobników, których chcemy skrzyżować:
- Losowy - pary do krzyżowania dobierane są w sposób losowy.
- Z najlepszym - odnajdujemy najlepiej przystosowanego osobnika i krzyżujemy go z wszystkimi pozostałymi.
- Najlepszy zostaje - sposób podobny do powyższego, z tym, że najlepszy osobnik zostaje włączony do nowej populacji.
Mutacje
Mutacja to samoistna, losowa zmiana w genotypie. W przyrodzie powstaje w wyniku błędów reprodukcji lub uszkodzeń fizycznych i zwiększa różnorodność materiału genetycznego. Algorytm genetyczny symuluje zachodzenie mutacji. Prawdopodobieństwo jej zajścia to sprawa indywidualna każdego programu, lecz jego wartość powinna być bardzo niska, gdyż inaczej w wynikach pojawi się dużo losowości, a ewentualne korzystne zmiany nie będą miały szans na utrwalenie się w populacji.
Zastosowania algorytmów genetycznych
Wynaleziono już wiele zastosowań algorytmów genetycznych. Spośród ciekawszych, można wymienić:
- Obliczanie ekstremów funkcji.
- Rozwiązywanie problemów zbyt skomplikowanych do rozwiązania tradycyjnymi metodami, jeśli nie interesuje nas absolutnie optymalne rozwiązanie (np. problem komiwojażera).
- Automatyczne generowanie wyrażeń matematycznych lub programów komputerowych rozwiązujących określony problem.
- Problemy, w których do końca sami nie wiemy, co konkretnie pragniemy uzyskać, lecz posiadamy jedynie pewne kryteria (np. projektowanie, planowanie).
Znane są przypadki wykorzystania algorytmów ewolucyjnych do projektowania kształtu komory silnika odrzutowego czy anteny o odpowiednich właściwościach.
Twierdzenie o schematach
Twierdzenie o schematach jest fundamentalnym twierdzeniem w teorii algorytmów genetycznych. Wyjaśnia ono, dlaczego one w ogóle działają i tłumaczy, w jaki sposób. Zacznijmy od kilku teoretycznych definicji pozwalających nam lepiej zrozumieć istotę sprawy.
Schemat to wzorzec opisujący podzbiór wszystkich ciągów podobnych do siebie ze względu na ustalone pozycje. Jeżeli mamy alfabet E, to schematy są słowami nad alfabetem E U {*} gdzie * może być dowolną literą alfabetu E. Przykład: Do schematu *T*K można dopasować słowa "PTAK", "ATAK", "STYK" - słowa pasujące do schematu nazywają się reprezentantami schematu.
Rząd schematu (liczność schematu) to liczba ustalonych pozycji w schemacie. Np. rząd schematu *T*K to 2.
Rozpiętość schematu to odległość między skrajnymi, ustalonymi pozycjami w schemacie. Rozpiętość schematu *T*K to 4-2=2. Rozpiętość schematu *B***I*RK* to 9-2=7.
Te teoretyczne definicje bardzo łatwo jest sprowadzić do algorytmów genetycznych. Słowami mogą być tutaj poszczególne chromosomy, a schematami - pewne kombinacje wybranych genów. Dalej będziemy dla uproszczenia posługiwać się chromosomami binarnymi, w których geny mogą przyjmować tylko wartości 1 i 0. Tabela przedstawia niektóre schematy w ośmiogenowym chromosomie i ich przykładowych reprezentantów:
| Schemat | Rząd | Rozpiętość | Reprezentanci |
| **1*001* | 4 | 4 | 01110011 10100011 00110010 |
| 1****0*1 | 3 | 7 | 11001011 10011001 10110011 |
Każdy chromosom jest reprezentantem bardzo wielu schematów (w powyższej tabeli ostatni przykład z drugiego schematu pasuje też do pierwszego).
Przystosowanie schematu to średnie przystosowanie wszystkich jego reprezentantów.
Można łatwo pokazać, że najlepszym przystosowaniem charakteryzują się schematy, których reprezentantami są najlepsze osobniki i jednocześnie nie są najgorsze. W czasie krzyżowania, mutacji i selekcji niektóre schematy będą powoli zanikać wraz z zanikaniem swych słabych reprezentantów. Za pomocą rachunku prawdopodobieństwa zbadano dokładnie, w jaki sposób schematy przenoszą się do następnego pokolenia, jednak my bez wnikania we wzory przedstawimy sformułowane przez Johna Hollanda twierdzenie o schematach:
Schematy małego rzędu, o małej rozpiętości i o przystosowaniu powyżej średniej otrzymują rosnącą wykładniczo liczbę reprezentantów w kolejnych generacjach algorytmu genetycznego.
Warunki te są zgodne z intuicją. Jeśli schemat jest małego rzędu i ma małą rozpiętość, jest mniejsza szansa, że w trakcie krzyżowania zostanie rozdzielony. Lepsze przystosowanie gwarantuje mu natomiast wejście jego reprezentantów do dalszego rozrodu.
Na podstawie tego twierdzenia powstała hipoteza głosząca, że przyczyną efektywności algorytmów genetycznych jest składanie krótkich ciągów genowych - cegiełek. Ma ona zastosowanie tylko, gdy między genami istnieją zależności. Ich istnienie pociąga za sobą konsekwencję możliwości utworzenia niedozwolonego osobnika w wyniku operacji krzyżowania. Wynika z tego, że geny, między którymi istnieją silne zależności, powinny zostać umieszczone blisko siebie tak, aby mogły utworzyć cegiełkę, a nie być rozdzielane w sposób losowy, doprowadzając do tworzenia dużej ilości nieprawidłowych osobników.
Gotowe biblioteki
Aby rozwiązywać problemy za pomocą algorytmów genetycznych, nie jest konieczne samodzielne programowanie całego mechanizmu. Biblioteka Genetic Algorithm Utility Library dostępna na zasadach open-source oferuje szkielety wszystkich niezbędnych mechanizmów, do których należy tylko dopisać funkcje odpowiedzialne za rozwiązywanie konkretnego problemu. Oprócz zaimplementowanych wielu wariantów poszczególnych części algorytmu, potrafi też przeprowadzać obliczenia na systemach wieloprocesorowych.
Strona WWW projektu: http://gaul.sourceforge.net
Zakończenie
Piękno algorytmów ewolucyjnych polega na tym, iż opierają się na teorii, której sporo ludzi na złość cioci zaprzecza. Wystarczy tylko uruchomić odpowiedni program i można na własne oczy przekonać się, że nawet pozornie losowe zmiany mają ewolucyjny sens i prowadzą do lepszego przystosowania populacji. Algorytmy ewolucyjne próbuje się z powodzeniem stosować do rozwiązywania coraz większej liczby problemów - jeśli jesteśmy w stanie coś przedstawić za pomocą wiarygodnej kombinacji genów, pozostaje już tylko programowanie i oczekiwanie na wynik.
Aktualna wersja zawsze dostępna na stronie: http://www.zyxist.com
Źródło: Tomasz "Zyx" Jędrzejewski
Licencja: Creative Commons - użycie niekomercyjne - bez utworów zależnych